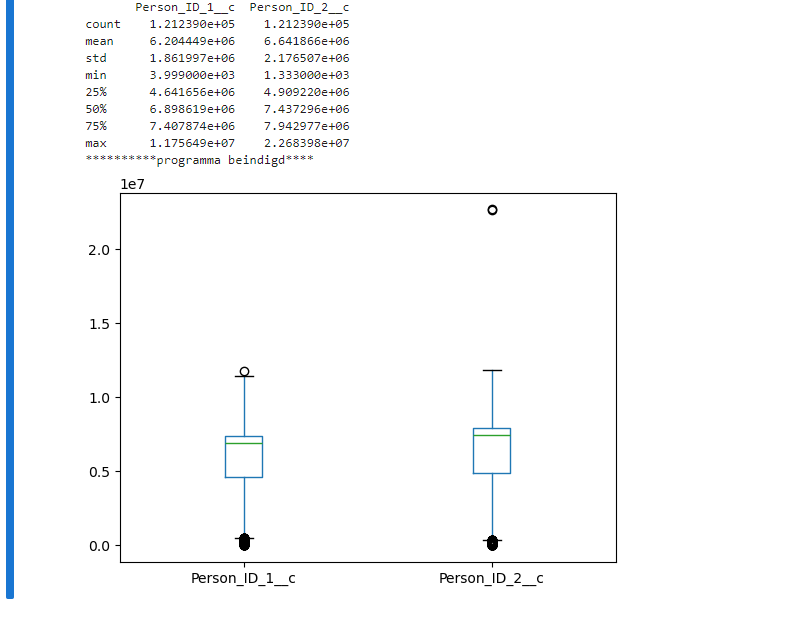
Below, a programme is given on the univariate statistics.
import pandas as pd
import sqlalchemy as sa
import matplotlib.pyplot as plt
import numpy as np
table_name = 'MIGRATED_DIVORCE_SETTLEMENT__C'
connection_string = "DRIVER={ODBC Driver 17 for SQL Server};SERVER=DESKTOP-8J58OIP\MSSQLSERVER_19;DATABASE=Speel;UID=sa;PWD=AAaa11!!"
connection_url = sa.engine.URL.create("mssql+pyodbc", query={"odbc_connect": connection_string})
engine = sa.engine.create_engine(connection_url)
with engine.begin() as conn:
df = pd.read_sql_query(sa.text("SELECT * FROM Rapportage." + table_name), conn)
onderzoek = df[['Person_ID_1__c','Person_ID_2__c']].apply(pd.to_numeric).dropna()
print(onderzoek.info())
print(onderzoek.head())
print(onderzoek.describe())
onderzoek.boxplot(column=['Person_ID_1__c','Person_ID_2__c'], grid = False)
print('**********programma beindigd****')