Teradata recently introduced the concept of pivoting in its sql. The idea is relatively straightforward. A column is selected that has some distinct values. Pivoting then implies that the distinct values are translated into columns. Doing so another value is used to derive the actual content in the columns. This can be a sum, maximum or any other aggregate.
Let us start with a table. Its content is:
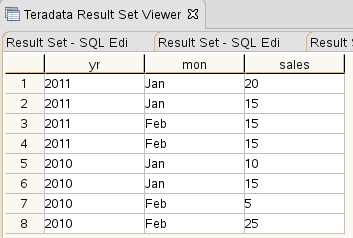
Let us use yr as the column that is pivoted. It has 2010 and 2011 as distinct values. We will have “2010” and “2011” as new columns. These columns are loaded with aggregates that are derived from another column, sales.
Let us look at the code:
SELECT "2010" as sales_2010, "2011" as sales_2011
FROM (select yr, sales from s1)s1
PIVOT (SUM(sales) FOR yr IN (2010,2011)) tmp;
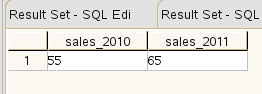
Notice that we use an inline query as the source. This inline query only contains yr and sales. Column yr is translated into two columns: 2010 and 2011. The end result will be one row with two two columns. The values in the row will be an aggregate (=sum) on sales.
So, we get:
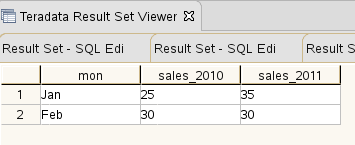
We can also retain an extra column from the original table. Let us retain “mon”. The code then gets:
SELECT mon, "2010" as sales_2010, "2011" as sales_2011 FROM (select yr, mon, sales from s1)s1 PIVOT (SUM(sales) FOR yr IN (2010,2011)) tmp;
And the result is: