A view on Oracle
24 October, 2010 11.00pm
I was able to play around with an Oracle tool 'Spotlight'. This tool is written by the very same group that also wrote Toad, the famous client tool for Oracle applications.
Spotlight is easy to install. After installation, one must make to connection to an Oracle instance. This showed itsself to be straightforward. After that, one might start playing around with Spotlight.
I started several sessions on the Oracle server. This can be seen in the top left corner, when "total users" is shown. This stands at 9 users.
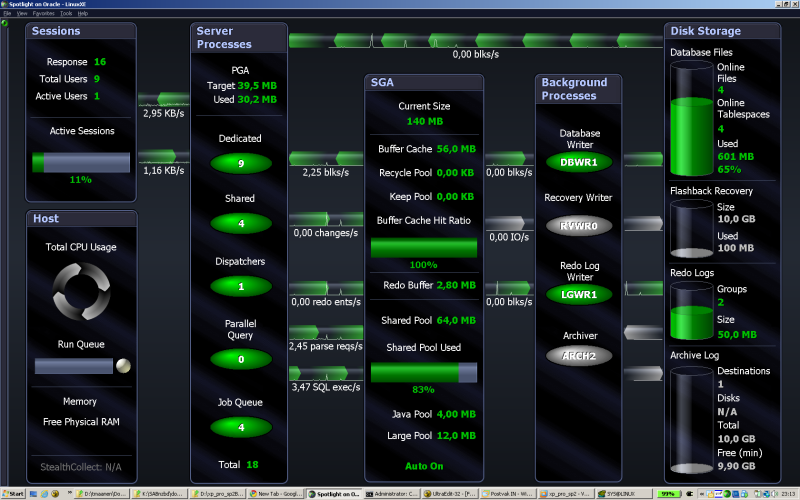
The next step was to relate this number 9 to other numbers in the diagram. We know that each user gets his own session. We also know that such a session is given a dedicated PGA memory chunk. We then see that under the PGA 9 dedicated server processes are allocated to the users.
Next to the Server processes, we have the SGA. This SGA stands for the System Global Area - which is a shared memory meant for the Oracle programme itsself, data buffers and control parameters. Within this SGA, we have memory structures that are meant to store data buffers (called the database buffer cache). I understand that during a read process, data are retrieved from a disk and stored in the buffer. After that these data are sent to the user. When a second read is issued, with the same data request, such data can be retrieved from the buffer in stead of the disk. This then saves I/O time.
I read somewhere that the size of the SGA should be around 40-50% of the internal memory of the server. In this case, the server has an internal memory of around 500 MB. If we take 40-50%, we get somewhere within the 200-250 MB of SGA. Apprently, the installation procedure of Oracle came to a slightly different solution. Only 140 MB was allocated for the SGA. However, I would say that this is in same order of magnitude as the recommended 40-50%.
A view on Oracle
28 October, 2010 11.00pm
Below, I give an example on how to classify records.
Let us start with a set of records that must be classified.
| Identifier | Internal Indicator | External Name |
| 1 | appel15 | elstar |
| 2 | appel23 | granny |
| 3 | peer12 | bergamot |
| 4 | peer26 | boerengroen |
| 5 | peer18 | Juttepeer |
We have 5 records that are identified with a number: 1, 2, 3 etc. We have an internal name (like appel15) and an external name that can be used to refer to an item that can be understood by n external party.
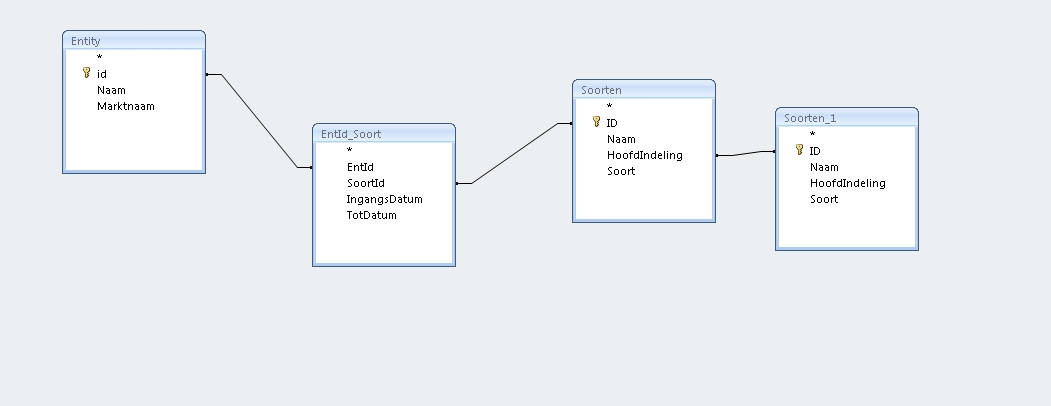
Let us turn to the classification table:
| IDentifier | Naam | HoofdIndeling | Soort |
| 1 | Fruit | 2 | Appel |
| 2 | Voeding | ||
| 3 | Kleur | Rood | |
| 4 | Fruit | 2 | Peer |
| 5 | Kleur | Geel |
We have three classifactions: "Fruit","Voeding","Kleur". These classifactions can be used concurrently: eg. appel15 might be fruit, might be belonging to "Voeding" or might have a Kleur.
For some classifications, we have several possible values: Fruit can be either "appel" or "peer". Likewise kleur can be "Rood" or "Geel". We can then see that an item like "appel15" might be Fruit, indicated by "appel", likewise appel23 can also be Fruit, indicated by "appel". Whereas peer12 can be Fruit, indicated by "peer".
It is also important to note that Fruit ("appel", "peer") has a parent classification that is labelled as "Voeding". Hence appel15 is Fruit that is a subgroup of "Voeding". Likewise peer12 is Fruit, but also a subgroup of "Voeding".
We can also create a table that links these two tables. This allows us to specify which record belongs to what classification. This table may look like:
| itemIdentifier | ClassificationIdentifier |
| 1 | 1 |
| 2 | 1 |
| 3 | 4 |
| 4 | 4 |
| 5 | 4 |
| 1 | 3 |
| 2 | 5 |
| 3 | 3 |
| 4 | 3 |
| 5 | 5 |
This can be queried with next set-up: Entity contains the records that must be classified; Soorten contains the classification, whereas Soorten_1 is a view that allows to select of parent values (like "Voeding").
Sending mail with Powershell
7 October, 2010 11.00pmI appreciate Powershell that is nowavailable at no costs from Microsoft. It is a scripting tool that allows us to execute:
- ordinary MS DOS command
- write programmes
- create and execute shell scripts
An example can be found below. In this script, I send an Email message with an attachment. As Powershell is built on a Net framework, it is possible to use objects that stem from .Net.
$hostname = 'laptop'
$date = Get-Date
$output = “Script was run on ” + $hostname + ” at ” + $date + ”. Please see the attachment for related information.”
write-host $output
$mail = new-object System.Net.Mail.MailMessage
$mail.From = new-object System.Net.Mail.MailAddress(“Toma.Vanmaanen@wxs.nl“)
$mail.To.Add(“Tomb.Vanmaanen@wxs.nl”)
$smtpserver = “smtp.wxs.nl”
$mail.Subject = “Irrelevant Message.”
$mail.Body = $output
$mail.Attachments.Add('C:\index.html')
$smtp = new-object System.Net.Mail.SmtpClient($smtpserver)
$smtp.Send($mail)
This script can be run from the command line as: >"C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe" D:\tmaanen\Documents\WindowsPowerShell\SendMail.ps1
ADO for .NET
1 September, 2010 11.00pm
Tonight, I tried to access an Oracle database with ADO for .NET. I read a few articles and it was claimed that accessing a database with ADO for .NET is relatively easy. I wanted to verify that claim. To make it short: using ADO for .NET is easy.
The idea is that objects are created upon which methods can be used to accomplish something (here: accessing a database).
I used Powershell to execute a script with ADO for .NET. This tool can be downloaded from Microsoft. It offers an environment that allows to run scripts. Such a script can be a human readable file with extension "ps1". Hence one may assume that Powershell is yet another programming tool like Perl. On the other hand, it is also a shell, much like MS-DOS. This mixture makes it extremely flexible. Moreover the environment is very easy to access: invoking the shell allows you to enter a script. Clicking on "run" runs the script. Likewise, one may enter a command (like dir, ls or get-childitem) that can be run.
To set the correct permission to run such a script, one must issue the command "Set-ExecutionPolicy Unrestricted". After that a script was run that looked like
It is also neceassry to have Oracle Data Provider for .NETinstaller. This can be verified by looking at the availability of an ODP.NET directory within the products directory in the client environment on the PC where the programmes are run. If it is not available, it can be installed from the Oracle installation files.
The script.
# Load the ODP assembly
[Reflection.Assembly]::LoadFile("C:\app\FlipDeBeer\product\11.1.0\client_1\ODP.NET\bin\1.x\Oracle.DataAccess.dll")
#connect to Oracle
$constr = "User Id=hr;Password=bunvegin;Data Source=LINUX"
$conn= New-Object Oracle.DataAccess.Client.OracleConnection($constr)
$conn.Open()
# Create a datareader for a SQL statement
$sql="select * from hr.employees"
$command = New-Object Oracle.DataAccess.Client.OracleCommand( $sql,$conn)
$reader=$command.ExecuteReader()
# Write out the result set structure
for ($i=0;$i -lt $reader.FieldCount;$i++) {
Write-Host $reader.GetName($i) $reader.GetDataTypeName($i)
}
# Write out the results
while ($reader.read()) {
$employee_id=$reader.GetDecimal(0)
$first_name=$reader.GetString(1)
$last_name=$reader.GetString(2)
Write-Host "$employee_id $first_name $last_name "
}
I understand this scripts as follows:
- We first create an object that allows methods to be created upon that read Oracle. This object is called conn. It allows to connect to Oracle.
- We then create a reader object, called reader.
- The remainder of the script is dedicated to the task of reading data from table "employees"
A more elaborate example can be found here, here or here, the latter with an OLE DB connection or here, the latter with an ODBC connection. A similar programme may run on a MySQL server database. The only thing necessary seems to be the installation of a MySQL connector ADO for .NET.
[Reflection.Assembly]::LoadFile("C:\Program Files\MySQL\MySQL Connector Net 1.0.10\Binaries\.NET 1.1\MySql.Data.dll")
$connectionString = "server=Linux.lan;uid=tom;pwd=bunvegin;database=tom;"
$connection = New-Object MySql.Data.MySqlClient.MySqlConnection
$connection.ConnectionString = $connectionString
$connection.Open()
# Create a datareader for a SQL statement
$sql="select * from tom.tom3"
$command = New-Object MySql.Data.MySqlClient.MySqlCommand($sql, $connection)
$reader=$command.ExecuteReader()
# Write out the result set structure
for ($i=0;$i -lt $reader.FieldCount;$i++) {
Write-Host $reader.GetName($i) $reader.GetDataTypeName($i)
}
# Write out the results
while ($reader.read()) {
$idtom=$reader.GetDecimal(0)
Write-Host "$idtom "
}
An example that is based on ODBC can be found here .
Producttypes
1 September, 2010 11.00pm
A few days ago, I noticed an easy to implement data model that allows typology of products. See
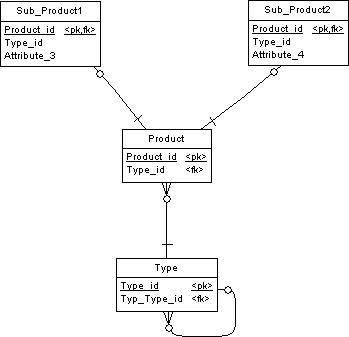
The idea is that we have an hierachy in which type descriptions are enclosed. This entity has a relation to itself that allows to have several layers of the hierachy in one table.
This table may look like:
1 - reference to type 1 |
attributes type 1 |
100 - reference to higher level |
2 - reference to type |
attributes type 2 |
100 - reference to higher level |
100 - reference to type 100 |
attributes type 100 |
- |
We also have a product table that has a foreign key reference to the type table. Other attributes in the product table describe the product. It is also possible that an additional table is needed to cover for attributes that are specific to a certain subgroup of the products. In these case, we assume that we have two subgroups that need additional attribtes. An example might be a group of products that has "services" as subgroup and "inventory items"as another subgroup. Special attributes that are related to services are attributes like availability and level of competence. Other attributes that are related to inventory are floorspace, durability.
Declarative roles
25 August, 2010 9.45pm
Only recently, I saw a beautiful picture on how to model declarative roles in a data model. See
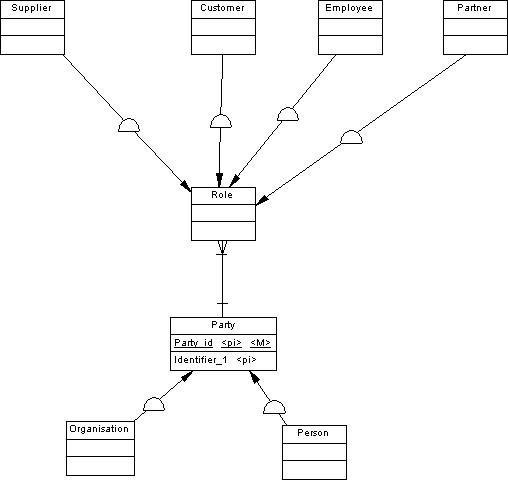
Brilliantly in its simplicity. The idea is that we are dealing with persons or organisations that act in a specific role (customer, employee). We would like to see that a party (an organisation and or person) may act in different roles simultaneously, like employee and customer. We then split the party (organisation or person) from the role. We have a 1 to n relation between party and role to allow for more roles that a party plays. From role we inherit common attributes into entitities that contain the specific attributes for a role (like social security number in employee, the Chambre of Commerce number in supplier etc.
This is called a declarative role as we do not collect the attributes that belong to the relation - like orders from a party - customer relation. We only want to show how a party might model the world around him: his customers, employees etc.
In many cases, we would like to see contextual roles: roles that exist since a particular activity has taken place (the sale, a project, an order etc). We then have to add the activity to the role in an 1 to n relationship. See
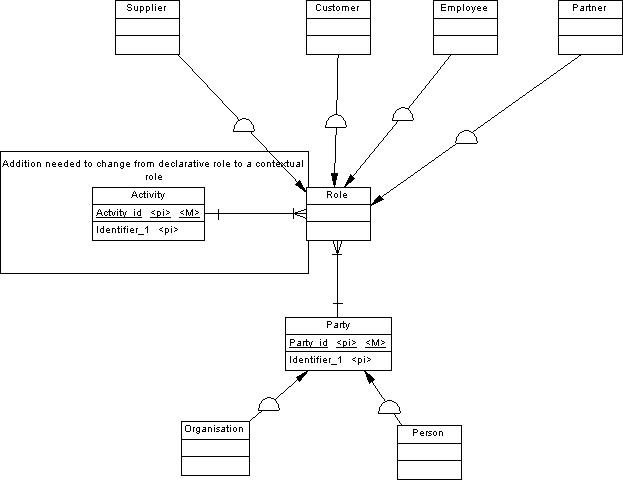
. Doing so, we are able to store the information from a party that buys (role!) a product (activity!). That same party may act as a project worker (role!) in a project (activity!). That very same project (activity!) may need projectworkers (roles!) that are taken up by some employees (parties!).
Database access
18 August, 2010 9.45pm
Recently I joined a company that used a nice tool to connect to different relational databases. The name was DbVisualizer. As it was for commercial usage, this organisation paid its license fee. I was really pleased with this tool.
Upon return home, I was pleased to see that it also has a free version (called DbVizualizer Free) that seems to have the same functionalities as the commercial version. At least, I did not yet discover major discrepancies between the commercial and the free version.
Installation is straight forward. If a new connection is to opened, one needs to get the java drivers (some are provided, others (like Oracle) not).
However adding a new java driver is well explained in the help file - it was a no-brainer.
A nice alternative is SQuirreL SQL Client that is open source software. So, if you want to stay away from commercial software, one can always use this alternative.
Calculate differences
25 June, 2010 10.45pmI recently had the problem how to calculate the difference between two tables. The idea was that two similar tables were provided (one with a snapshot of yesterday and one with a snapshot of today) and only the new records were of of interest. How to get that difference. The simple answer is to use the minus operator:
select * from (select * from hr.rotcas_oor minus select * from hr.rotcas_mut) a;
The question then arises if we have an alternative.
After some google-actions I got an alternative:
select * from hr.rotcas_oor where dbms_utility.get_hash_value(CNF||ORIG||NUM_DOS_CRD||MOTIF||TER ||M_ ||DEVMTERM||DEV ||CD||NROFSRC||NRMAT ||DATE_CAS ||MONTANT || SERIE ||RACINE||SIEGE||CPTE||DV_CAS010,1,power(2,28)-1) not in (select dbms_utility.get_hash_value(CNF||ORIG||NUM_DOS_CRD||MOTIF||TER ||M_ ||DEVMTERM||DEV ||CD||NROFSRC||NRMAT ||DATE_CAS ||MONTANT || SERIE ||RACINE||SIEGE||CPTE||DV_CAS010,1,power(2,28)-1) from hr.rotcas_mut);
Was it successful?
No not really. The first alternative gave an answer within 20 seconds with two 600K row tables and the alternative took more than 15 minutes. Dunno why.
A Query with calculations
24 June, 2010 10.45pm
I read a beautiful article on the possibility to combine calculations and a query. This allows us to do queries without the necessity of constantly having to write the interim results to a table on the disk. Instead, we combine a query and calculations and we will store our results somewhere in memory. This could be nice if we would like to use these results in a subsequent calculation that will lead to a final target table. Again: doing so, we avoid the necessity to use interim tables.
How do we do this. We first create two objects that will contain the intermediate table:
create or replace type purchases_record as object (product_id varchar2(8), time_key date, customer_id varchar2(10), ship_date date) create or replace type purchases_table as table of purchases_record
If we have this object, an object where we can store the table, we may continue to continue a structure that refers to a table.
create or replace package cur_pack as type ref_cur_type is ref cursor; end cur_pack;
Our programme then looks like:
create or replace FUNCTION TRANSFORM(inputrecs IN cur_pack.ref_cur_type) RETURN purchases_table PIPELINED IS product_id varchar2(8); time_key date; customer_id varchar2(10); ship_date date; BEGIN loop fetch inputrecs into product_id, time_key, customer_id, ship_date; exit when inputrecs%notfound; --here we have the calculations but it might be a lot more complicated customer_id:=2000+customer_id; pipe row(purchases_record(product_id, time_key, customer_id, ship_date)); end loop; close inputrecs; return; END TRANSFORM;
Records are read. They can then be changed in the subsequent calculations. Subsequently the records can be written to a structure that is defined before.
The function can be invoked by "select * from table(transform(cursor(select * from in_put)))". The input is table in_put that obeys to the structure defined before. The records are then stored in a cursor that is sent to the function that is created in the programme.
.
Retrieve data from an XML file with XSL
31 May, 2010 10.45pm
It is possible to use XSL to retrieve data from an XML file. An XML file is then seen as a datastore; the XSL file is seen as a means to translate the XML file into an HTML file. We then need something to link th XML file to the XSL file.
Let us take en example. The XML file (here) contains a set of names and addresses.
The XSL file (here) describes how the data are to be retrieved from the XML file.
We then have a third element, a Java script file (here) that links the XML file to the XSL transformation file.
If the three files are stored in, say a directory on the webserver, we see the result (here). Ik you do see an expected result, check your settings as you need to enable jsp script.
Writing a design document
11 May, 2010 10.45pm
I am often asked to give an example on how a technical design of a data warehouse should look like; what should it contain, what level should it have etc.
A technical design should describe how a table in a data warehouse is loaded. Hence a data warehouse with a hundred tables should have a hundred technical designs. In each technical design, we should be informed on the purpose of the table, what steps are to be taken before the table is loaded, how the table is loaded and what steps are to be taken after the load.
We should also be informed on the level of individual attributes what their source is, how the attributes are processed and what look-ups are used etc.
An example of such technical design can be found here: DetailDesign.pdf. I admit that this design has a serious flaw as it is written in Dutch. That is a serious flaw as its usage is now limited to Dutch speakers. If the organisation has a resource who is a non-Dutch speaking person, he can not develop or test an application that is created from this design. Writer of the design: plse write your beautiful design in English next time.
.
Reading XML
29 April, 2010 11.04pm
XML files can be read in an Oracle table. This is not extremely difficult.
Let us first create a table in which XML data can be stored; see: createTable.sql
We then create a directory that can be accessed from Oracle; see: createDir.sql
We can then store this XML file in the directory that was just created; see xml
This PL/SQL programme may then read the XML file; see plsql
It looks rather straightforward
.
Secure Shell
October, 26th, 2009 on too late
Recently, I created a secure shell connection. I used a very nice document ( here ) to do this.
I used the CopSSH server as the server application and Putty as the client application.
To create the keys, I used the Puttygen application that is available on the same location as Putty.
Here, I did something different than indicated in the document. I allowed the OpenSHH server to create a public/private key pair.
I then imported the private key.
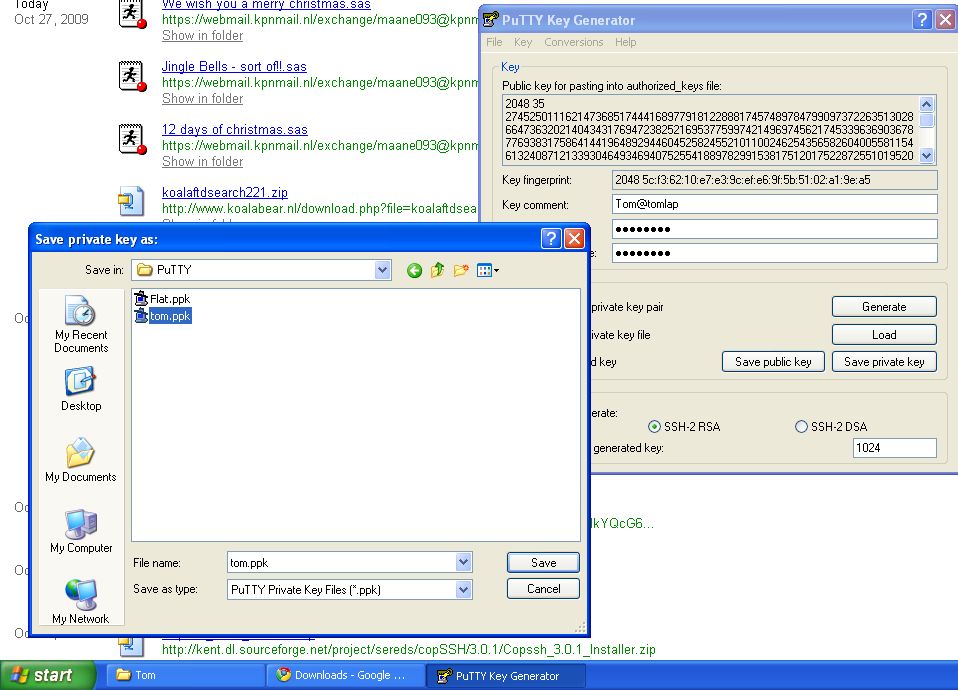
I then saved the private key with the ppk extension. This latter extension is recognisable by Putty.
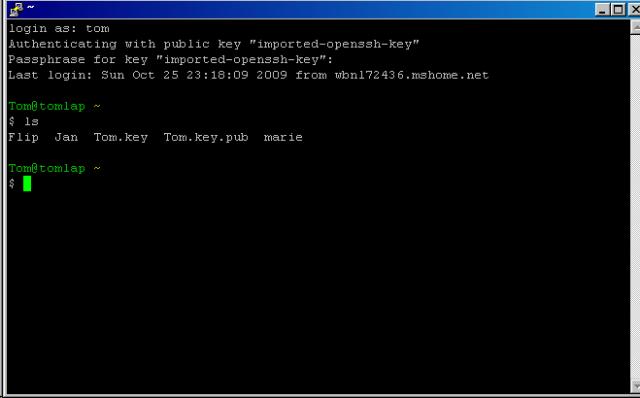
As a first step a secure shell connection was established. See screen below for a screenshot on how such secure shell connection looks like.
Once this worked, I included in Putty a port forward statement. This allows a connection between a randomly chosen local port with foreign port on which an application on the server listens. Let us assume that on the server on which CopSSH is stored, we also have a telnet server that listens to port 23. We then issue the statement: L100 [telnetserver]:23, which connects local port 100 to remote port 23 to which telnet server listens.
We then start the secure shell connection. If this works, we start the telnet client that is directed to the localhost and we include port 100 to which the telnet client should talk to.
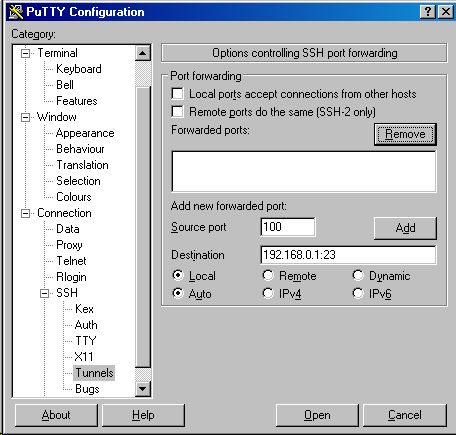
Via the secure shell, this is propagated to the port 23 on the server.
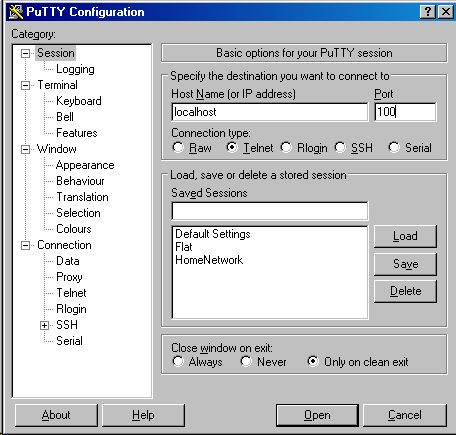
Note on the screenshot that the server to be accessed is the localhost. As port, we use port 100. This signal is propagated to the server. We have to logon with a userid/password that is used on the server.
SAS
October, 7th, 2009 on 9.55 pm
I am now engaged in a SAS assignment. Working again with SAS.
I get the opinion that SAS is composed of several languages that have little in common. It is a mixture of ANSI SQL, own SAS and elements that seem to be derived from other elements. Today I worked with the proc tabulate from SAS which seems to be borrowed from a table mark up tool.
This leds to the necessity of learning quite a few elements by heart - much like any natural language. One could also see this when you visit a bookshop to get a good SAS book. Titles like: "Learning SAS by Example: A Programmer's Guide", "Professional SAS Programming Shortcuts: Over 1,000 Ways to Improve Your SAS Programs" and "SAS Programming by Example " ressemble books that aim at learning a natural languages. There we have the feared "idiom" books, that contain meanings that are not predictable from the usual meanings of their elements.
Below, I added some scripts that may come of hand when a certain situation must be solved.
A method to export all SAS datasets from a library to a directory. Tables will be sent in CSV format. |
|
A method to join a large table with a small table. The small table is set as a hash object in memory. |
|
A procedure to write tables. Provides us with the number of records per class. |
|
Another procedure to write tables. Provides us with a calculation within each cell. |
|
The _method option gives some background on the proc sql - much like the explain option in Oracle. |
|
Some nonsense to get everybody angry. |
|
A way to scan a file for words. |
|
Get your SAS settings!. |
Nothing to do
August, 9th, 2009 on 4.23 pm
Recently I bought a nice Synology DS109. I use this machine to store my files on. So I use the Synology 109 as an external hard drive. However, this machine is capable to do much more. It contains a MySQL DBMS, a FTP server and a web server. This attracted my attention on a lazy Sunday afternoon.
Getting the webserver going is really easy: the user interface contains some buttons. If you click on "enable web station", the web server works. Clicking again turns it off. One could then access the webserver from any PC in the network. This is straightforward. However, I wanted to get one step further: open this website to the Internet.
Opening the website to the Internet is also rather easy. I went to the router and I forwarded the port of the Synology machine to the outside world. The network is connected to the Internet via an IP number. When someone on the Internet uses that IP number in his browser, the request is forwarded to the Synology machine.
But does it work? I would like to see if someone from outside is able to see my website as I can see from inside my network. This was checked with http://www.totalvalidator.com . This site allows you to insert your URL and retrieve a print screen on how the website looks in any given webbrowser. As I got a nice picture from my website, I was certain that the website could be seen by anyone outside.
External Drive Broken
May, 10th, 2009 on 9:56 pm
On a Friday, my external drive broke. It was a My Book World Edition External 500GB Network Storage device from Western Digital. The lights were flashing nicely, the hard disk inside seemed to spindle nicely but the contact was gone. And, of course no backup was ever made. Backup is for sissies.
I assumed that the hard disk was still ok but either the network card or something else around the hard disk was broke. In principle, this would mean that all data were still there, but they were unreachable.
After some attempts (all in vain), I decided to set the great step: remove the hard disk from the storage. I must admit: it was a big step for me. Removing the hard disk was quite straightforward though. It was attached with about ten screws, that allowed me to get the hard disk.
The next step was to buy a hard drive case. It was a sitecom USB 3.5'' Hard Drive Case. The hard drive could be stored in this case. I now had an USB external drive that could be accessed. But how?
I assumed that some kind of Linux format was used. Hence putting the USB external drive into a Windows box is not a good idea.
Fortunately, I also have an Ubuntu / Linux box that could be used. I attached the USB external drive to this box and I issued the command "sudo fdisk -l". This came back with a nice overview of all disks, including my USB external drive. Between the output, I read:
/dev/sdc4 506 60801 484327620 fd Linux raid autodetect
This was the indication that the data were seen as a /dev/sdc4, just waiting to be rescued.
I then created a so-called mount point on my system by creating a directory that can subsequently be used a starting point for reference to the files on the USB drive. Creating a mount point is done with sudo mkdir Western
Subsequently, I mounted the USB external drive with: sudo mount -t ext3 /dev/sdc4 /media/Western
And there they were: my files, just waiting to be copied; ls -l gave:
drwx------ 2 root root 16384 2008-02-29 08:42 lost+found drws--S--- 9 www-data www-data 4096 2009-04-06 14:00 NETTHDDNIEUW drwsrwsrwx 2 www-data www-data 4096 2008-10-05 21:58 PUBLIC
Copying will take a week, but it is going on, nice and sure.
I realize, it nows sounds easy but my total time investment was 7 hours. And when you type in "problems with WD MyBookWorld" in Google, you will get lots of long frustrating stories.
Wikopedia
April, 1st, 2009 on 14:47 pm
One cannot escape Wikis. Nowadays, every department has its own "Wiki". They are easy to install, easy to maintain and fun to use.
On a lazy saturday night, I started installing such a Wiki. The first step is to download a set of files. I went to MediaWiki ( www.mediawiki.org ). This site hosts the sourcefiles of Wikipedia itsself. One can download this set of files as a tar file ( mediawiki-1.14.0.tar.gz ). This set of files is a series of php files.
I then downloaded a "WAMP" server, which is a combination of Apache webserver (hence the "A" in WAMP), MySQL (hence "M"in WAMP) and a PHP interpreter (the P), all to be installed on a a Windows server. It can be found on a French site ( http://www.wampserver.com/en/download.php ).
Once WAMP is installed, one must copy the MediaWiki files into the directory that is used to get the the site from. In my case, the directory is "c:\wamp\www'). In your case, it might be a different directory; this depends on the configuration of the webserver.
Before the first usage of the Wiki, it is important to realize what we have. We have a set of php files, that will generate html files that will be sent via the Apache webserver to the user. The user is able to add content to Wiki via signals to the webserver that can be interpreted with the help of php files. The content is stored in a MySQL database. We then need a schema and a user of the MySQL database that will be used to store the content in the MySQL database. We then need to create a schema in the MySQL database. We must also create a user in the MySQL database. This can be done via standard client tools on the server itsself. We log on to the MySQL database as "root"(no password) and we create a schema and a user. Once that is done, we can proceed.
Invoking the Wiki is straightforward: we check if all services (MySQL and Apache) run. We then open a brwoser and we access the site by typing in th name of the server that hosts Apache. Upon first usage, the necessery parameter (such as scheme name and a user name) are asked and off we go.
That is really all.
But if you want the easy way, we can also download an image file from www.mindtouch.com. This allows you to start a virtual machine with a Wiki preinstalled. This is almost too easy; but it is true:
Small, amaller, smallest
April, 1st, 2009 on 14:47 pm
From time to time I wonder why all instances must be that big. Installing Oracle 11, requires you to download 1 Gig; installing SQL Server Express requires a half Gig. Why should it be that big and enormeous. Ok, I realize that lots of logica is shipped with the products and I realize that this requires space.
But what happens if we only want to store a couple of thousand records? Is it really necessary to use these heavy DBMSen?
One could take a look at Firebird. See http://www.firebirdsql.org . One could download a package that only has 10MB. This contains both the server and client elements. With it, one could also download a quick reference that clearly describes how to make a quick start.
And the performance is ok. No problem about this.
Only one problem remains. After the installation, we have a service on the server and a command line interface. Big question: how to access the data. Either, we decide to use the command line (with the price to learn another language), or we decide to opt for a general pupose client tool. This latter is made possible since we could also download ODBC drivers.
Perl
March 30, 2009 on 15:17 pm
I do not know about you, but most of the times, I use graphical tools to get anything done. Inserting data into a database: start Access and create a link upon which data can be added to a data. Insert a new large table: start Informatica, create a workflow to add the new large table to the data warehouse. Create a report: start Business Object to get it done. Do some analysis: start Excel. etc. etc.
However, old fashioned programming could do the job also. I remember to have used Perl in old days. To see how it looked like, I installed Perl and started to write some code.
Installing Perl is really easy: from "ActivePerl", one could download an installation package that makes installing Perl easy sailing. See: www.activestate.com .
After that programs can be written and executed from the command line. See below the harvest of one day:
#!/usr/bin/perl
use DBI;
# procedures
sub geef_dbhandle
#
# Deze procedure geeft een db handle terug die hoort bij een Firebird database die op server pong staat
# Er is een extra controle of deze db handle wel bruikbaar is
# De paramaters van de Firebird database zitten hard coded in de procedure
#
{
$dbh = DBI->connect('dbi:ODBC:Firebird', 'tom', 'bunvegin');
my $supported = $dbh->get_info(46);
if ($supported == 0)
{print "transactions are not supported". "\n";}
elsif ($supported == 1)
{print "transactions can only contain Data Manipulation Language (DML) statements (e.g. select, insert, update, delete) and not Data Definition Language (DDL) statements". "\n";}
elsif ($supported == 2)
{print "both DML and DDL statements are allowed". "\n";}
elsif ($supported == 3)
{print "transactions can only contain DML statements.". "\n";}
elsif ($supported == 4)
{print "transactions can only contain DML statements. DDL statements encountered in a transaction are ignored.". "\n";}
else {print "Tja er is iets goed mis". "\n";};
return $dbh;
}
######
sub geef_aantal_records {
my ($dbh, $tabel) = @_;
my $sth = $dbh->prepare("select count(*) from $tabel");
print "Number of fields " . ($sth->{NUM_OF_FIELDS}). "\n";
$sth->execute;
my @row;
while (@row = $sth->fetchrow_array) { # retrieve one row
print "Aantal records " , join(", ", @row), "\n";
return 1;
}
}
sub geef_inhoud_tabel{
my ($dbh, $tabel) = @_;
my $sth = $dbh->prepare("select * from $tabel");
$sth->execute;
my $ref = $sth->fetchall_arrayref({});
my $aantal_rij = 0 + @{$ref};
print "Aantal rijen in ",$tabel," is ", $aantal_rij, "\n";
print "Ingelezen kolommen zijn: ",join (", ", keys %{$ref->[0]}), "\n";
foreach $r (@{$ref})
{
print join(", ", (values %$r)), "\n";
}
print "Number of rows returned is ", 0 + @{$ref}, "\n";
return 1;
}
sub geef_inhoud_kolom{
my ($dbh, $tabel, $k) = @_;
my $sth = $dbh->prepare("select * from $tabel");
$sth->execute;
my @row;
while (@row = $sth->fetchrow_array) { # retrieve one row
print @row[$k] , "\n";
}
return 1;
}
sub voeg_record_toe{
my ($dbh, $tabel) = @_;
my $sthi = $dbh->prepare("select * from $tabel");
$sthi->execute;
my @row;
while (@row = $sthi->fetchrow_array) { # retrieve one row
my $stmt = "INSERT INTO FLIP_KOPIE (RT_DEPART_FROM ,RT_ARRIVE_TO) VALUES('" . @row[3] . "','" . @row[4] . "')";
my $sthd = $dbh->prepare($stmt);
$sthd->execute;
}
return 1;
}
$dbh = geef_dbhandle;
$i = geef_aantal_records($dbh,"FLIP");
$i = geef_inhoud_tabel($dbh,"FLIP");
$i = geef_inhoud_kolom($dbh,"FLIP",3);
$i = voeg_record_toe($dbh,"FLIP");
As you can see, Perl is very staightforward. Each program starts with a line ( #!/usr/bin/perl ), that identifies the code as being a Perl program.
An additional set of functions will be used in the program to connect to database tables. This is indicated with "use DBI;". This set of functions allows me to get connected to database tables via ODBC.
The first step is get a database handle. The code to be used is "$dbh = DBI->connect('dbi:ODBC:Firebird', 'tom', 'bunvegin');". Here "Firebird" is the ODBC dsn on the machine. "tom" and "bunvegin" are the userid and password. Having the userid and password allows you to connect to a database that is accessed via ODBC.
The SQL to be executed is inserted as an argument into a function "my $sth = $dbh->prepare("select * from $tabel");". When executed "$sth->execute", the results from the SQL are returned to the program. The results can be captured with "while (@row = $sth->fetchrow_array) {print @row[$k] , "\n";};".
Ingres
March 24, 2009 on 21:02 pm
The history of Ingres DBMS is interesting. It started at the University of California at Berkeley in the dark ages - early seventies. From it, other products started, like Sybase, Postgres/ PostgreSQL, SQL Server. Here, we are at Adam of the DBMS. Even stronger: it still exists. It can be downloaded at http://esd.ingres.com/ .
Once downloaded, you have the choice to either install a server version or a client version. In principle, the server edition is installed only once and the client version as many as the number of clients. In a windows environment, this is rather staight forward.
At first sight, the administration is intimidating. I counted 17 client programmes on the server machines that were meant to maintain this DBMS. Oracle is far beaten here. The client installation is similar: you get a total of 16 applications. Even worse: no grouping is applied, no indication where to start. And in the documention, no "primer", no "quick start". Yes the documentation standards have not changed changed since the birth of Ingres.
I understood that the client is in fact a server process that must be connected to the server. After some time, I discovered that such information must be entered in the "virtual node definition".
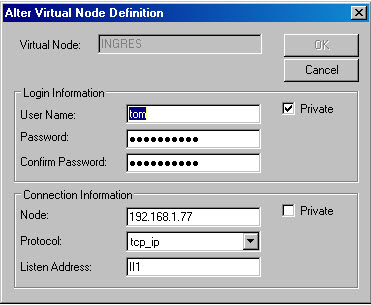
The user name and password refer to the server where the Ingres database is located. The node information is derived from the server installation: node is the server indication (in this case an IP number). The protocol that is used can be seen in the server installation. I understood that II1 is related to tcp_ip protocol.
When that is done, you must create an ODBC connection.
Fortunately, the ODBC drivers are installed with the client and the creation of an ODBC link can be started dirctly. I decided to use a "public" user, that only requires a password to enter. The names of the Vnode is derived from the "virtual node definition". The database name is taken from the server installation.
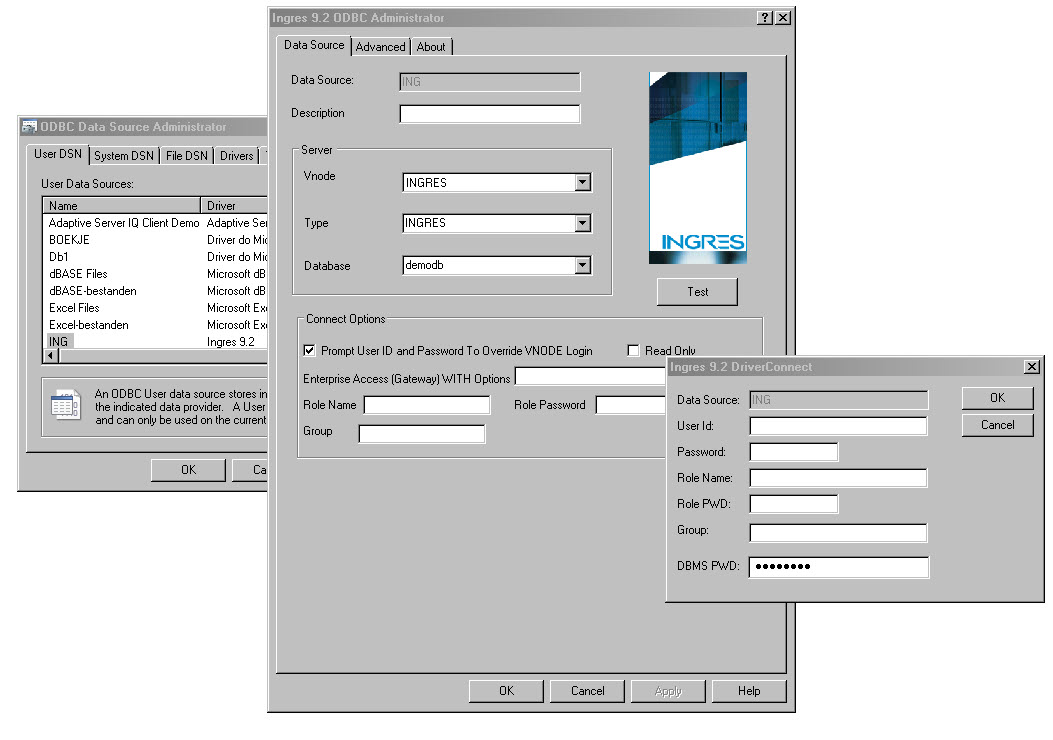
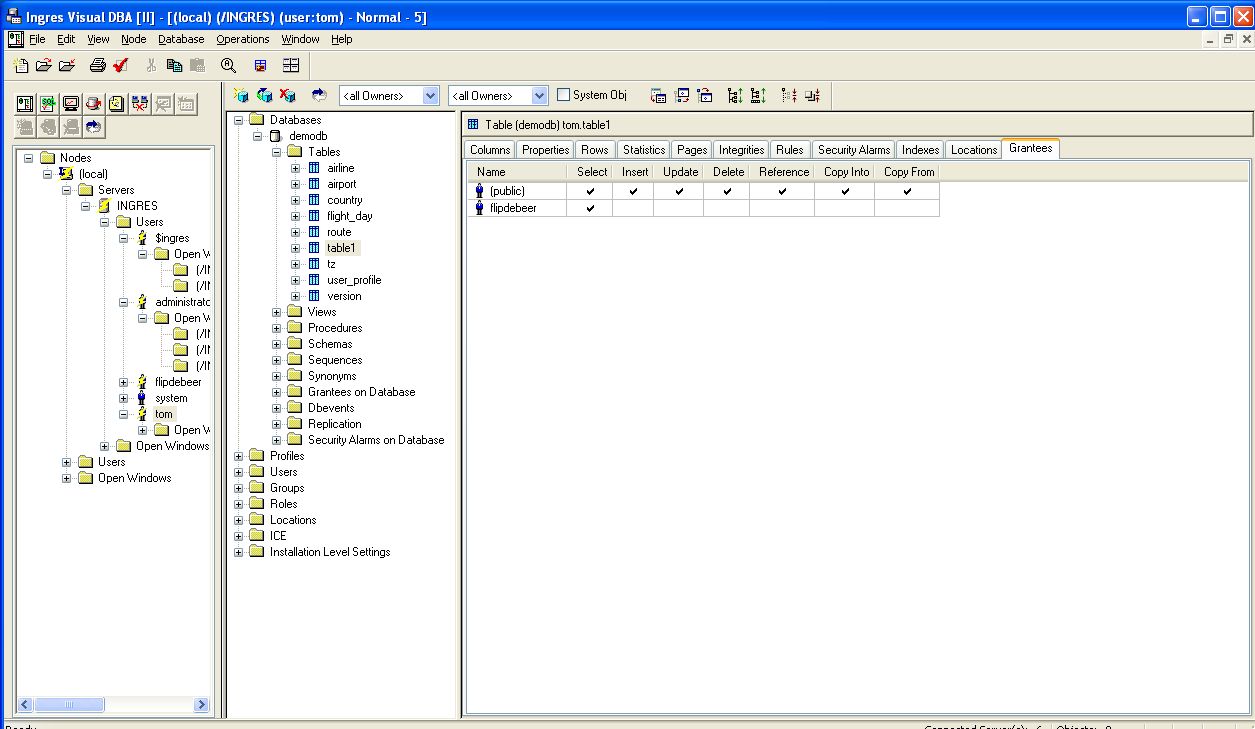
Finally, I set the priviliges for the table. This is done on the server with the client tool "Visual DBA". You start with the user that owns the scheme where the table is located. From that perspective, one could set the privs to the public user, as shown in next image.
External tables in Oracle Warehouse Builder
March 17, 2009 on 23:15 pm
I am starting to like the Oracle warehouse Builder. Apologize! Here, we have a tool that is cheap and offers nice functionality. I admit: it is not as easy to have it connected to non-Oracle resources as Informatica. It does not have the functionality as SAS. But, nevertheless I like it.
Why, let us say because of the price.
But I have a minor problem with reading external flat files.
One should take three steps
Step 1 is to create an entry for the file itsself
Step 2 is to create a definition for the external table. This is based upon the definition of the file in step 1
Step 3 is to generate code for the extrnal table and to deploy it
But then, no records can be read, or, only a fraction is read. And at first sight all defintions are right. What to do?
I looked at the definition of the external table. There I saw next lines:
NOBADFILE
NODISCARDFILE
NOLOGFILE
I changed it manually into:
BADFILE 'BAD.TXT'
NODISCARDFILE
LOGFILE 'LOG.TXT'
Re-creating the external table and Re-reading the records quickly revealed the error.
Another access to ODBC via Oracle
March 09, 2009 on 23:05 pm
I tried another access method from Oracle to an ODBC data source. In this case, I used Oracle 11. The nice feature of Oracle 11 is that the heterogeneous service is directly installed. In previous versions, you need to to install these services seperately. I tried to access a non-Oracle database from Oracle 11, based on a standard installation of this Oracle version. I choose to access Postgres. This is an open-source DBMS that complies to ODBC.
Step 1. Create an ODBC connection. Choose the system-DSN option. Let us call this ODBC connection "Postgres".
Step 2. In Oracle 11, you also have a directory \hs\admin. Rename the inithsodbc sample file into initDb1.ora . The Db1 returns within the file as a parameter. The contents of the file is:
HS_FDS_CONNECT_INFO = Db1 HS_FDS_TRACE_LEVEL = ON
Step 3. Add to the listener.ora file next lines; I use port 1522 to have a new listener listen to:
LISTENERDB1DSN =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = WBNL72436.corp.capgemini.com)(PORT = 1522))
)
)
SID_LIST_LISTENERDB1DSN =
(SID_LIST =
(SID_DESC =
(SID_NAME = Db1)
(ORACLE_HOME = C:\Oracle\product\11.1.0\db_1)
(PROGRAM = dg4odbc)
)
(SID_DESC=
(SID_NAME=Postgres)
(ORACLE_HOME=C:\ORACLE\product\11.1.0\db_1)
(PROGRAM=dg4odbc)
)
)
In this example I set up the access to two different ODBC sources: one of them is the Postgres database. The Sid_name of this datasource is "Postgres".
Step 4. Add to the tnsnames.ora file next lines - within tnsnames, the Sid_name "Postgres" is used - :
POSTGRES=
(DESCRIPTION=
(ADDRESS=
(PROTOCOL=TCP)
(HOST=localhost)
(PORT=1522)
)
(CONNECT_DATA=
(SID=Postgres))
(HS=OK))
Step 5. Start the listener from the command line with
lsnrctl start LISTENERDB1DSN
Step 6. Verify the existence of the POSTGRES database with "tnsping POSTGRES".
Step 7. Create a database link with
CREATE PUBLIC DATABASE LINK POSTGRES CONNECT TO "tom" IDENTIFIED BY "bunvegin" USING 'POSTGRES';
Here "tom" is the userid of the Postgres database and "bunvegin" is the password. Strangely enough, testing the database link gave an error. I attributed this error to a abnormality somewhere.
Step 8. Verify if data are retrieved from Postgres database with select a."id", a."name" from "tom"."eentabel"@postgres a;. "id" and "name" are attributes in a table "eentabel", that is stored in scheme "tom".
Once data are retrieved, we succeeded. I took me 4 hours to get here. Oef.
Access SQL Server via Oracle
March 04, 2009 on 23:05 pm
I realize that we may encounter the situation whereby we want to access SQL Server data from within Oracle. I encountered this when a SQL Server database was used as a source for an Oracle data warehouse.
Creating the link from within Oracle to SQLServer requires 8 steps.
Step 1. Create an ODBC connection. Choose the system-DSN option. Let us call this ODBC connection "SQLSERVER".
Step 2. I assume you have the heterogeneous services installed. In that case, you also have a directory \hs\admin. Rename the inithsodbc sample file into initSQLSERVER.ora . The SQLSERVER is the SID that we will use to access the SQLSERVER database. The contect of the file reads as:
HS_FDS_CONNECT_INFO = SQLSERVER HS_FDS_TRACE_LEVEL = OFF
Step 3. Add to the listener.ora file next lines:
LISTENERMYSQLSERVERDSN =
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1522))
(ADDRESS=(PROTOCOL=ipc)(KEY=PNPKEY)))
SID_LIST_LISTENERMYSQLSERVERDSN=
(SID_LIST=
(SID_DESC=
(SID_NAME=SQLSERVER)
(ORACLE_HOME = C:\oracle\product\10.1.0\db_1)
(PROGRAM=hsodbc)
)
)
Step 4. Add to the tnsnames.ora file next lines:
MYSQLSERVERDSN =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1522))
(CONNECT_DATA=(SID=SQLSERVER))
(HS=OK)
)
Step 5. Start the listener from the command line with
lsnrctl start listenermysqlserverdsn
Note that this creates a service that is only started manually. If you would like to have this available after a reboot, you might want to change this into the Automatic mode.
Step 6. Verify the existence of the SQLSERVER database with "tnsping MYSQLSERVERDSN".
Step 7. Create a database link with
CREATE PUBLIC DATABASE LINK SQLSERVER
CONNECT TO TOM
IDENTIFIED BY {PWD}
USING 'MYSQLSERVERDSN';
Here TOM is the name of the sqlserver database and {PSW} stands for the password.
Step 8. Verify if data are retrieved from SQLSERVER with select * from {TABLE}@SQLSERVER.
Once data are retrieved, we succeeded. If not, take a coffee and relax.
Run OWB packages in a scripts
February 17, 2009 on 23:05 pmOnce, I created a package with Oracle Warehouse Builder. I went to the sequence of creating such a package, validate it, generate code and deployment. I was curious if it would be possible to run this package outside the Oracle Enterprise Manager. Well it showed itself possible with a small script:
set serveroutput on
DECLARE
flip VARCHAR2 (100);
BEGIN
owbsys.wb_workspace_management.set_workspace('MY_WORKSPACE','REP_OWNER');
expense_wh.lees_expense.main (flip,
1000,
1000,
'SET_BASED_FAIL_OVER_TO_ROW_BASED'
);
dbms_output.put_line('###Result is '||flip);
END;
Why do I like it? Well running such packages outside the Oracle EM requires less resources on the workstation. I had a workstation, that was not able to use the Oracle EM. Now, I am able to run such packages outside this tool.
Explain plans in Oracle
December 13, 2008 on 23:20 pmYou may wonder how Oracle undertakes the query. Is Oracle using the indices that are povided, or, does Oracle do a full table scan. Often we don't know and we want to know as we would like to see if an index is used (and should be maintained).
Oracle has two command to do such investigation:
explain plan for [some query]; and select * from table(dbms_xplan.display);
In the first statement data are collected on the explain plan. The second statement displays these data as a table. Note that the data are estimates; the query itsself is not yet executed.
Two interesting SQLs
December 10, 2008 on 23:15 pmIt is possible to apply several logical steps in one SQL statement. Such logical steps are (1) insert a record, (2) update a record and (3) delete a record. An example
merge into links using links1 on (links.id=links1.id) when matched then update set links.naam=links1.naam delete where links.id=3 when not matched then insert(id, naam) values(links1.id, links1.naam);
In data warehousing, such sequences are often used. You may receive a file that must be compared to an old file. When matches are found, the record must be updated, when not matched the record must be inserted. One might use such a merge statement.
Then analytical functions.
Such functions allow to calculate subtotals and merge these subtotals into the original table.
SELECT empno, deptno, ROW_NUMBER( ) OVER (PARTITION BY deptno ORDER BY deptno, empno) RIJ, MAX(EMPNO) OVER (PARTITION BY deptno) GROOT, MIN(EMPNO) OVER (PARTITION BY deptno) KLEIN, COUNT(*) OVER (PARTITION BY deptno) DEPT_COUNT FROM emp;
Using external tables with datapump organization - Oracle
December 7, 2008 on 23:25 pmOracle has the concept of an external table. The external table looks like a table but the data are stored in an external file. Whenever the data from a table must be shown, the external file is accessed to retrieve the data.
Let us look at the script to create an external table; let us assume that this script is created on the target database.:
CREATE TABLE SCOTT.LINKS_EXT
(
ID NUMBER(38),
NAAM VARCHAR2(10 BYTE)
)
ORGANIZATION EXTERNAL
( TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY TEST_DIR
ACCESS PARAMETERS
( )
LOCATION (TEST_DIR:'EMP.EXP')
)
We see that the data can be stored in a file "EMP.EXP". This is file that is stored in a directory "TEST_DIR". This directory is related to a directory "C:\ORADATA", which is linked in statement whereby the directory is stored. We may have this definition on the target database. At first, the file "EMP.EXT" is not available - it must be created on the source database. It is possible to create the "EMP.EXT' in two steps:
Step 1: create the binary file on the source database with
CREATE TABLE SCOTT.LINKS_EXT3
(
ID ,
NAAM
)
ORGANIZATION EXTERNAL
( TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY TEST_DIR
ACCESS PARAMETERS
( )
LOCATION (TEST_DIR:'EMP.EXP')
)
AS SELECT * FROM LINKS;
Step 2: copy the binary file "EMP.EXP" to the directory that is indicated on the target database. We then have the file on the target database. We then see the data on the target database.
copy table spaces
November 30, 2008 on 23:30 pmAnother trick to copy data from database A to database B, can be done with a direct copy of the tablespace. This can be done in actions around database A that is composed of exporting the metadata (expdp transport_tablespaces=transport dumpfile=transport.dmp directory=transport) to a file that can be copied to anothr Oracle instance. The tablespace itsself must be taken offline and set to readonly: alter tablespace transport read only;
We can then copy the metadata (here transport.dmp and the files that created the tablespace to a new Oracle environment.
We then import the metadata into the new instance B with impdp transport_datafiles='c:\transport.dbf' dumpfile=transport.dmp directory=transport .
CDC revisited
November 30, 2008 on 22:56 pm
Previously, I described the situation that a CDC mechanism was implemented in Oracle. The idea is that a copy op the table is created that contains changes to the original table. The chnges can be read at intervals. Subsequently the changes are processed in a data warehouse/
This article brings the line of reason one step further. In this section,I introduce a new concept whereby the changed data are automatically sent to a view in the database. It is also possible to create a dataflow from the view to another database on which the data warehouse is stored.
As a first step, we create a dataflow from a change table. This is done in two commands: command 1 creates the dataflow; command 2 creates the change table from where the dataflow starts.
exec dbms_cdc_publish.create_change_set(- change_set_name =>'SYNC_SET1',- description => 'Kommentaar',- change_source_name => 'SYNC_SOURCE') EXECUTE DBMS_LOGMNR_CDC_PUBLISH.CREATE_CHANGE_TABLE (OWNER => 'scott',- CHANGE_TABLE_NAME => 'emp_cdc', - CHANGE_SET_NAME => 'SYNC_SET1', - SOURCE_SCHEMA => 'scott', - SOURCE_TABLE => 'emp',- COLUMN_TYPE_LIST => 'empno number, ename varchar2(10), job varchar2(9), mgr - number, hiredate date, deptno number', - CAPTURE_VALUES => 'both', - RS_ID => 'y', - ROW_ID => 'y', - USER_ID => 'y', - TIMESTAMP => 'n', - OBJECT_ID => 'n', - SOURCE_COLMAP => 'y', - TARGET_COLMAP => 'y', - OPTIONS_STRING => null); note: in Oracle 11, we have to include the option DDL_MARKERS=>'n',
We now have a change table (emp_cdc) from where a dataflow starts to which anybody within the database may subscribe. The dataflow can be addressed as SYNC_SET1, a name under which the dataflow is known inside the database.
After that a subscription can be started that leads to a view where the changed data can be seen. This goes with:
exec dbms_cdc_subscribe.create_subscription(- change_set_name=>'SYNC_SET1',- description=>'Kommentaar',- subscription_name=>'SUBS2'); exec dbms_cdc_subscribe.subscribe(- subscription_name=>'SUBS2',- source_schema=>'scott',- source_table=>'emp',- column_list=>'empno, ename, job, mgr, hiredate, deptno',- subscriber_view=>'v_emp'); exec dbms_cdc_subscribe.activate_subscription(subscription_name=>'SUBS2');
We now have a view where the changed data can be stored. It is also possible to create multiple views, each with a different subscription-name.
Getting data in the view is done in 3 commands:
command 1: load the changed data in the view exec dbms_cdc_subscribe.extend_window(subscription_name=>'SUBS2'); command 2: copy data to the data warehouse command 3: purge data from the view: exec dbms_cdc_subscribe.purge_window(subscription_name=>'SUBS2');
The second command (copy data to the data warehouse) requires attention. We must establish a so-called database link to read the data from the database into the data warehouse. This can be done in several steps. We must first establish that we can access the server on which the view on changed data is stored. This can be done with a ping command (ping [servername]) that shows whether the server can be seen from another machine. After that, we may start a tnsping [database], that shows whether the Oracle instance can be seen. Once we know that we can see the Oracle instance, we create a database link with: create database link "pong" connect to scott identified by "tiger" using [database]. If that is done, we can read the data from the view by SELECT DEPTNO, EMPNO, ENAME, HIREDATE, JOB, MGR FROM SUBSCRIBER.V_EMP@[database link];
The effects of partitioning
November 23, 2008 on 22:56 pm
It is possible to partition a table into seperate physical units. In Oracle, such a table is called a partitioned table. This can be extremely effective. A small example might show this. I have a table with about 2 million records. I want to know how many records have a certain value. This could be investigated with a statement like "select count(*) from [table] where [attribute] = '[value]'". I did not use an index or anything on the table. It took me 1 minute and 10 seconds to get the answer. This is logical as Oracle must do a full table scan.
In a second attempt, a similar table was created, but then the table was divided into several partitions: one partition for each value of a certain attribute. After that, the same SQL was fired: again the number of records was asked for which the attribute had a certain value. This time, the time was shortened to 21 seconds. This can be explained as only one partition was to be investigated.
Let us go into technical details.
The exact SQL was: "select count(*) from customer_fact1d where member_status='Live';". Again: the table customer_fact1d has no indices. A full table scan is needed to accomplish anything. The table had 2,4 GB.
I then recreated the table with the table partitioned according to values of "member_status". This was done with next SQL statement:
CREATE TABLE ORBIT.CUSTOMER_FACT1D_PART
(
REOPENED NUMBER(38),
INACTIVE_CLOSED NUMBER(38),
...
)
TABLESPACE ORBIT
PARTITION BY LIST (MEMBER_STATUS)
(
PARTITION PART_505 VALUES ('Inactive')
PARTITION PART_212 VALUES ('Live')
...
);
The addition to the "create table" statement is "partition by list ...". This forces the table to be divided according to values of "member_status". After that the same SQL was issued: "select count(*) from customer_fact1d where member_status='Live';" This led to considerable time gains. This can be explained as the physical file that contains the partition only contains 0,6 GB.
SQL> set timing on
SQL> select count(*) from customer_fact1d;
Verstreken: 00:01:15.78
SQL> select count(*) from customer_fact1d where member_status='Live';
COUNT(*)
----------
479262
Verstreken: 00:01:10.56
SQL> select count(*) from customer_fact1d_part where member_status='Live';
COUNT(*)
----------
479262
Verstreken: 00:00:21.46
SQL>
Three ways to include SQL in Oracle PL/SQL
November 1, 2008 on 23:06 pm
PL/SQL is the 3GL language that aims at seamless processing SQL commands. It is the language that is added to the Oracle DBMS.
One could include SQL commands to a PL/SQL program in three ways:
- One could include your SQL commands directly in PL/SQL. Coomonly known as embedded SQL. Usage of such statements is limited: for example, the CREATE TABLE statement can not be included directly in the PL/SQL.
- Then, one could also use a command "EXECUTE IMMEDIATE" that allows a SQL ommand to be executed immediately. Known as native SQL.
- Finally, we have the DBMS package that allows SQL commands to be executed thru the a DBMS package. This consists of first parsing a string , followed by the execution of such statement.
Below, a program is given that shows the differences.
CREATE OR REPLACE PROCEDURE SCOTT.vul_tabel1(nrows_in IN INTEGER := 30)
IS
i INTEGER:=1;
v_Tot INTEGER;
cur PLS_INTEGER := DBMS_SQL.OPEN_CURSOR;
fdbk PLS_INTEGER;
BEGIN
-- EMBEDDED SQL
WHILE i <= nrows_in
LOOP
insert into SCOTT.TABEL (A) values(i);
i := i + 1;
END LOOP;
COMMIT;
SELECT COUNT(*) INTO v_Tot FROM SCOTT.TABEL;
DBMS_OUTPUT.PUT_LINE('Aantal rijen = ' || v_Tot);
-- NATIVE SQL
EXECUTE IMMEDIATE 'TRUNCATE TABLE SCOTT.TABEL';
SELECT COUNT(*) INTO v_Tot FROM SCOTT.TABEL;
DBMS_OUTPUT.PUT_LINE('Aantal rijen = ' || v_Tot);
-- dbms package
DBMS_SQL.PARSE (cur, 'insert into SCOTT.TABEL (A) values(99)', DBMS_SQL.NATIVE);
fdbk := DBMS_SQL.EXECUTE (cur);
DBMS_SQL.CLOSE_CURSOR (cur);
COMMIT;
SELECT COUNT(*) INTO v_Tot FROM SCOTT.TABEL;
DBMS_OUTPUT.PUT_LINE('Aantal rijen = ' || v_Tot);
END vul_tabel1;
/
Create dimensions in Oracle
November 1, 2008 on 23:06 pm
Oracle has the concept of a dimension. A dimension can be seen as metadata that describe the relation within an existing table. Such metadata can subsequently be used to improve query performance. This implies that a dimension itsself does not contain the data. The data remain in the table. Only the relationsship between the data is described.
The relationship in the table can be described as attributes that determine other attributes. As an example, one may think of a customer_id that determines the customer name, his address, his telephone etc.
It is also possible that some attributes have a child-parent relationship. Think of a town (=child) that lies in a country (parent).
The concept of dimension is linked to the concept of a materialized view. The materialized view can be used in a query rewrite to retrieve the outcomes from a query directly from the materialized view in stead of underlying large tables.
The dimension then makes the optimizer aware of possible synonymns that may extend the usage of data from a materialized view.
As an example, let us start with a query that retrieves outcomes from two large tables. Whenever attributes are used that are also used in a materialized view, the optimizer may decide to retrieve the data from the materialized view instead.
It can also be true that attributes are used in the query that are described in the dimension. The optimizer then translates the attributes thru the dimension into attributes that are used in a materialized view. The result is that a query that is formulated in other attributes as the materialized view can nevertheless take advantage of the materialized view.
A very nice example can be found on swiss website . The author then shows that optimzer really uses a materialized view after the formulation of a dimension.
Writing the contents of a table to a file
October 19, 2008 on 22:26 pmIn this article, I give an example on how to write the contents of a table to a flat file. I use Oracle as the DBMS. I assume that in this Oracle DBMS, we have a directory that allows flat files to be an integral part of the Oracle DBMS. I have a directory "SAMPLEDATA" that may contain such flat files.
I open the flat file with the statement: utl_file.fopen('SAMPLEDATA','sample1.txt','W').
I can write strings to the flat file with: utl_file.put_line(f,s).
Once the file is opened, I open a table. The table contents is first stored in a so-called cursor, that can be opened with: OPEN T1Cursor.
When the table / cursor is opened, I start a loop that reads every record. Whenever a record is read, the contents is transferred to a string (with FETCH T1Cursor into x_DEPTNO, x_DNAME, x_LOC and s:= '"'||x_DEPTNO||'"'||';'||'"'|| x_DNAME||'"'||';'||'"'|| x_LOC||'"'. Once the string is filled, it is written to the external file.
The programme:
CREATE OR REPLACE PROCEDURE SCOTT.SCHRIJF IS
f utl_file.file_type;
s varchar2(200):='DEPTNO; DNAME; LOC';
CURSOR T1Cursor IS
SELECT DEPTNO, DNAME, LOC
FROM
DEPT;
x_DEPTNO DEPT.DEPTNO%TYPE;
x_DNAME DEPT.DNAME%TYPE;
x_LOC DEPT.LOC%TYPE;
x_DATUM DATE:= SYSDATE;
begin
f := utl_file.fopen('SAMPLEDATA','sample1.txt','W');
utl_file.put_line(f,s);
OPEN T1Cursor;
LOOP
FETCH T1Cursor into x_DEPTNO, x_DNAME, x_LOC;
EXIT WHEN T1Cursor%NOTFOUND;
s:= '"'||x_DEPTNO||'"'||';'||'"'|| x_DNAME||'"'||';'||'"'|| x_LOC||'"';
utl_file.put_line(f,s);
END LOOP;
CLOSE T1Cursor;
utl_file.put_line(f,x_DATUM);
utl_file.fclose(f);
end;
/
Reading from flat files in Oracle
October 13, 2008 on 11:15 pm
It is possible to read flat files by the Oracle DBMS.
Oracle advises to create a directory to store the files on. This can be one by the command "CREATE DIRECTORY SAMPLEDATA AS 'c:\temp';" that can be issued from the sqlplus command line. The necessary privilegs are set by "GRANT read, write ON DIRECTORY sampledata TO PUBLIC;". Once that is done, we may create a file on the directory - known as c:\temp on the operating system. Let us assume, we have created a file 'sample1.txt' with the brilliant text 'onzin'.
This can be shown from Oracle by the exceution of the PL/SQL procedure below:
First the programme:
CREATE OR REPLACE PROCEDURE SCOTT.SCHRIJF IS
f utl_file.file_type;
s varchar2(200);
begin
f := utl_file.fopen('SAMPLEDATA','sample1.txt','R');
utl_file.get_line(f,s);
utl_file.fclose(f);
dbms_output.put_line(s);
end;
/
The procedure can be issued by:
SQL> exec schrijf
onzin
Maintenance of Fact tables in a data warehouse
October 13, 2008 on 9:45 pmIn this article, I will present a small PL/SQL programme that maintains a Fact table in a data warehouse.
I assume that we live in a data warehouse where every time a new batch of data is sent to the data warehouse. The new batch of data must be appended to the existing fact table. However, we are not sure if the batch has not been processed before. If we would append the data without checking, the data would be loaded twice. Hence we must introduce a check on a previous load. This is labeled cleaning: delete the records that may belong to a previous data load.
We also realize that the data in the batch have business keys. As we use surrogate keys, the business keys must be translated into surrogate keys. This can done via a look-up to the dimension table.
The program does 3 things:
1: Clean the data warehouse table with records that refer to the same period as the period for which new records are sent to the data warehouse. This will be used if the same data set is reloaded into the data warehouse. In that case, old records must first be deleted from the dat warehouse before loading can be started.
2: Translate business keys into surrogate keys. Such translation is derived thru a lookup in the dimension table
3: append the newly delivered data into the data warehouse.
First the programme:
CREATE OR REPLACE PROCEDURE SCOTT.INVOEG (VERWERKDATUM IN VARCHAR) IS
tmpVar NUMBER;
D_VERWERKDATUM DATE;
CURSOR T1Cursor IS
SELECT PRIMKEY AS SURKEY_VRUCHT, AANTAL_VERKOCHT, DATUM
FROM
(SELECT * FROM INVOER_FEIT WHERE to_CHAR(DATUM,'YYYYMMDD') = to_CHAR(D_VERWERKDATUM,'YYYYMMDD')) A,
(SELECT * FROM DIM_VRUCHT WHERE GELDIG='Y') B
WHERE A.NUMMER=B.NUMMER;
x_DATUM INVOER_FEIT.DATUM%TYPE;
x_AANTAL_VERKOCHT INVOER_FEIT.AANTAL_VERKOCHT%TYPE;
x_SURKEY_VRUCHT DIM_VRUCHT.PRIMKEY%TYPE;
x_BOEL INTEGER :=0;
BEGIN
tmpVar := 0;
-- Opschomingsprocedure
D_VERWERKDATUM:=to_DATE(VERWERKDATUM,'YYYYMMDD');
DELETE FROM SCOTT.FEIT_VRUCHT
WHERE
to_CHAR(DATUM,'YYYYMMDD') = to_CHAR(D_VERWERKDATUM,'YYYYMMDD') ;
--Gegevens toevoegen aan Feitentabel
OPEN T1Cursor;
LOOP
FETCH T1Cursor into x_SURKEY_VRUCHT, x_AANTAL_VERKOCHT, x_DATUM;
EXIT WHEN T1Cursor%NOTFOUND;
INSERT INTO SCOTT.FEIT_VRUCHT(SURKEY_VRUCHT, AANTAL_VERKOCHT, DATUM) VALUES (x_SURKEY_VRUCHT, x_AANTAL_VERKOCHT, x_DATUM);
END LOOP;
CLOSE T1Cursor;
COMMIT;
END INVOEG;
/
Maintenance of Dimension tables in a data warehouse
October 12, 2008 on 11:45 pmIn this article, I will present a small PL/SQL programme that maintains a dimension table in a data warehouse. This program uses the logic that is commonly known as a SCD type 2 dimension table.
This program can be copied directly into your Oracle client. After compilation, it can be run by issuing the EXEC command.
The program assumes a dimension that is loaded with data with two attributes: a/ a business key and b/ a description
The business key stems from the operational system. It can be seen as a primary key that is unique in the operational system.
However in the data warehouse, we can not assume that the business key can be used. We need to translate with an own key - the surrogate key that is used as a primary key in the data warehouse system.
We also assume that the data is always delivered as a full load: all data available are delivered.
Hence, the first situation is that a complete new record is delivered: the business key is delivered but is not yet known in the data warehouse. In that case the record is inserted in the data warehouse table.
The second situation is that the record exists in the data warehouse but the description is different from the one that is used in the data delivery.
In that case, a record in the data warehouse is closed and a new record with new data is inserted.
The third situation is that the record is not delivered but the record still exists in the datawarehouse.
First the programme:
CCREATE OR REPLACE PROCEDURE SCOTT.WERK
IS
CURSOR T1Cursor_Inserts IS
SELECT VRUCHT, NUMMER FROM SCOTT.INVOER_DIM_VRUCHT WHERE NUMMER NOT in (SELECT NUMMER FROM DIM_VRUCHT WHERE DATUM_UITGANG is NULL);
CURSOR T1Cursor_Updates IS
SELECT A.VRUCHT, A.NUMMER
FROM SCOTT.INVOER_DIM_VRUCHT A, SCOTT.DIM_VRUCHT B
WHERE A.NUMMER=B.NUMMER
AND A.VRUCHT != B.VRUCHT
AND B.GELDIG='Y';
x_VRUCHT EXT_TABLE_CSV.VRUCHT%TYPE DEFAULT 'Manadarijn';
x_NUMMER EXT_TABLE_CSV.NUMMER%TYPE DEFAULT -9999;
BEGIN
-- Toevoegen nwe records
OPEN T1Cursor_Inserts;
LOOP
FETCH T1Cursor_Inserts into x_VRUCHT,x_NUMMER;
EXIT WHEN T1Cursor_Inserts%NOTFOUND;
INSERT INTO DIM_VRUCHT (VRUCHT, NUMMER,PRIMKEY,DATUM_INGANG,GELDIG) VALUES(x_VRUCHT,x_NUMMER,SEQMAND.NEXTVAL,SYSDATE,'Y');
END LOOP;
COMMIT;
CLOSE T1Cursor_Inserts;
-- Afsluiten oude records
OPEN T1Cursor_Updates;
UPDATE DIM_VRUCHT
SET GELDIG = 'N', DATUM_UITGANG=SYSDATE
WHERE NUMMER IN
(SELECT A.NUMMER FROM SCOTT.INVOER_DIM_VRUCHT A, SCOTT.DIM_VRUCHT B
WHERE A.NUMMER=B.NUMMER
AND A.VRUCHT != B.VRUCHT
AND B.GELDIG='Y');
--Toevoegen geupdate records
LOOP
FETCH T1Cursor_Updates into x_VRUCHT,x_NUMMER;
EXIT WHEN T1Cursor_Updates%NOTFOUND;
INSERT INTO DIM_VRUCHT (VRUCHT, NUMMER,PRIMKEY,DATUM_INGANG,GELDIG) VALUES(x_VRUCHT,x_NUMMER,SEQMAND.NEXTVAL,SYSDATE,'Y');
END LOOP;
COMMIT;
CLOSE T1Cursor_Updates;
--verwerken niet aangeleverde dimensierecords
UPDATE DIM_VRUCHT
SET DATUM_UITGANG=SYSDATE
WHERE NUMMER NOT IN
(SELECT A.NUMMER FROM SCOTT.INVOER_DIM_VRUCHT A)
AND GELDIG='Y' AND DATUM_UITGANG IS NULL;
COMMIT;
END WERK;
/
the data delivery is stored in an extrnal table.
DROP TABLE SCOTT.INVOER_DIM_VRUCHT CASCADE CONSTRAINTS;
CREATE TABLE SCOTT.INVOER_DIM_VRUCHT
(
VRUCHT VARCHAR2(20 BYTE),
NUMMER NUMBER
)
ORGANIZATION EXTERNAL
( TYPE ORACLE_LOADER
DEFAULT DIRECTORY EXT_DIR
ACCESS PARAMETERS
( records delimited by newline
fields terminated by ';'
missing field values are null
(
VRUCHT,
NUMMER
)
)
LOCATION (EXT_DIR:'Invoer_dim_vrucht.csv')
)
REJECT LIMIT UNLIMITED
NOPARALLEL
NOMONITORING;
-- the Invoer_dim_vrucht.csv looks like:
appel;1;
dadel;10;
kiwi;9;
and the data warehouse table.
DROP TABLE SCOTT.DIM_VRUCHT CASCADE CONSTRAINTS;
CREATE TABLE SCOTT.DIM_VRUCHT
(
VRUCHT VARCHAR2(20 BYTE) NOT NULL,
NUMMER NUMBER NOT NULL,
PRIMKEY NUMBER,
DATUM_INGANG DATE NOT NULL,
DATUM_UITGANG DATE,
GELDIG CHAR(1 BYTE) NOT NULL
)
SET DEFINE OFF;
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('appel', 1, 43, TO_DATE('10/11/2008 22:25:27', 'MM/DD/YYYY HH24:MI:SS'), NULL,
'Y');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('peer', 9, 44, TO_DATE('10/11/2008 22:25:27', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('10/11/2008 23:30:09', 'MM/DD/YYYY HH24:MI:SS'),
'N');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('druif', 9, 46, TO_DATE('10/11/2008 22:52:00', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('10/11/2008 23:30:09', 'MM/DD/YYYY HH24:MI:SS'),
'N');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('banaan', 10, 47, TO_DATE('10/11/2008 23:05:34', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('10/11/2008 23:13:52', 'MM/DD/YYYY HH24:MI:SS'),
'N');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('dadel', 10, 48, TO_DATE('10/11/2008 23:13:52', 'MM/DD/YYYY HH24:MI:SS'), NULL,
'Y');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('druif', 9, 49, TO_DATE('10/11/2008 23:18:33', 'MM/DD/YYYY HH24:MI:SS'), TO_DATE('10/11/2008 23:30:09', 'MM/DD/YYYY HH24:MI:SS'),
'N');
Insert into DIM_VRUCHT
(VRUCHT, NUMMER, PRIMKEY, DATUM_INGANG, DATUM_UITGANG,
GELDIG)
Values
('kiwi', 9, 52, TO_DATE('10/11/2008 23:30:49', 'MM/DD/YYYY HH24:MI:SS'), NULL,
'Y');
COMMIT;
Copy data via PL/SQL
July 15, 2008 on 11:12 pmIn this small article, I will present a small Oracle program that copies a table from a table to another table. I like this small program: it is easy / small / directly implementable. The program can be copied and directly copied into sqplus. After compilation, it can be run with "EXEC program". If the procedure is called L_DM_DIM_ORDER_STS_E, we may start the progra with EXEC L_DM_DIM_ORDER_STS_E.
I will shortly discuss the program. First the program is installed in the database with the statement "CREATE PROCEDURE". Within the program, two variables are used (l_start_time and l_execution_id. These variable are used to store the time and the procedurename in an audit table. The latter is implemented with an INSERT INTO statement.
After that each row is read into an object (r_src). Within this object, we store the attributes from each row. Once the values are stored in r_src, we may write the values as an INSERT statement.
This type of procedures can be used when we load a data warehouse. A certain file is sent to a data warehouse. Once it is received, it will be copied into the data warehouse environment. This latter could be done via such a copy procedure.
CREATE OR REPLACE
PROCEDURE L_DM_DIM_ORDER_STS_E
IS
l_start_time CONSTANT DATE := SYSDATE ;
l_execution_id VARCHAR2(50) := 'L_DM_DIM_ORDER_STATUS';
BEGIN
execute immediate ('truncate table SCOTT.DEPTKOPIE');
INSERT INTO SCOTT.AUDITTABEL(TIJD, PROCJE) VALUES( l_start_time, l_execution_id);
For r_src IN (
SELECT DEPTNO FROM SCOTT.DEPT
) LOOP
BEGIN
insert into SCOTT.DEPTKOPIE (DEPTNO) values (r_src.DEPTNO);
END;
END LOOP;
COMMIT;
END L_DM_DIM_ORDER_STS_E;
/
Profiling data
June 22, 2008 on 10:23 pmProfiling data is an important part in the analysis of ETL flows. Roughly stated: ETL is all about getting data from a sourcing ystem to a target system. When the anlysis is undertaken, we need to know the contents of the sourcing system. We need to know for sure if the data comply to business rules. An example of such business rule is that a payment date always occurs after delivery date. We need to verify if that is true or not. Another example: the date of birth may never happen in the future. This must also be verified. During the analysis, we then get an idea whether the data are of good quality or not. If the data always are compliant, the future ETL does not need a modification. If the business rules are not followed, the ETL flow must deal with it, somehow.
In principle, such analysis can be done by a series of SQL statements. One could write per attribute in each table a series of SQL that verify each business rule. For each attribute, one writes a SQL that calculates the maximum, the minimum, the avarage, the median etc etc. This could then be compared to the ideas that one has with the business rules in the background. Again as an example a birth date: the maximum can on only be now (the SYSDATE); the minumum can only be a hundred years back. The average should be about 30-40 years in the past.
However, if thousands of attributes must be gone thru, this becomes cumbersome. One needs to look for an autmated procedure that could help you out.
Such programmes exist. Fortunately. Let me discuss three examples.
Example 1 is the wizard that resides in Oracle Warehouse Builder. This wizard allows profiling on so-called external tables that are imported in Oracle Warehouse Builder.
Example 2 is SQL Server 2008 that has profiling in it.
Example 3 is the freeware program "Profiler" that can be downloaded from www.arrah.in . It has a fully functional version that rolls for free for a limited period. After that, one should either turn the system clock back or pay for the product. The product is easy to install but two remarks are in order (1) the JDK version should be strictly obeyed en (2) it runs with the command "java Profiler". Important to know and no indication on it in the documentation.
Generate a report from Oracle
December 3, 2007 on 11:42 pmBelow, I give a script that enables us to generate reports directly from Oracle.
I admit: the lay-out is simple.
I admit: you have to do hand-coding yourself.
But, but, the handcoding is relatively simple. The results are directly visible. You may use Excel to view the reports. And they may be sent to all customers thru conventional methods of bursting reports. One may schedule to mail these reports to any customer you may.
To start, one must declare a directory from within SQL plus: create directory reports as ‘C:\reports’. This is a one-time declaration.
After that, the script below may be run. This creates a function within the scott schema. Subsequently the function may be run.
create or replace procedure print_reports_simple is
cursor c_direct_reports is
select
empno,
ename,
job,
hiredate,
sal
from
onzin; — view op table emp
wfile_handle utl_file.file_type;
v_wstring varchar2 (100);
v_header varchar2(100);
v_file varchar2(100);
v_date varchar2(20);
begin
v_header :=’empno’||chr(9)||’ename’||chr(9)||’job’||chr(9)||’hiredate’||chr(9)||’sal’;
v_file := ‘onzin.xls’;
wfile_handle := utl_file.fopen (’REPORTS’,v_file, ‘W’);
utl_file.put_line(wfile_handle,v_header);
for r in c_direct_reports loop
v_wstring := r.empno||chr(9)||r.ename||chr(9)||r.job||chr(9)||to_char(r.hiredate,’dd/mm/yyyy’)||chr(9)||r.sal;
utl_file.put_line(wfile_handle,v_wstring);
end loop;
utl_file.fclose (wfile_handle);
end print_reports_simple;
To calculate the difference in business days
December 2, 2007 on 11:42 pmBelow, you will find a script that calculates the number of business days between two dates in Oracle.
Unfortunately, Oracle does not know a function that automatically calculates the number of business days. I can imagine that Oracle does not have such a function. It is really dependant on local customs, regional settings and changing attitude. A small example: this year has the Christmas Eve on Monday, December 24. Most people would assume that Monday is not a normal business day and it should therefore be excluded from such calculation. I wish the programmer good luck to program such logic.
So you need to prgram such a function yourself. You might use the script below. Take care!
The scripts runs as follows:
create or replace FUNCTION bdays(start_date IN DATE, end_date IN DATE, region IN CHAR)
RETURN NUMBER
IS
retval NUMBER(15,7);
new_start_date date;
new_end_date date;
bdaystart number(15,15);
bdayend number(15,15);
BEGIN
new_start_date := start_date;
new_end_date := end_date;
– set defaults for business day start and end. Can be overridden per region
bdaystart := 7/24;
bdayend := 17/24;
if region=’Europe’ then
new_start_date := new_start_date + 9/24;
new_end_date := new_end_date + 9/24;
bdaystart := 9/24;
bdayend := 18.5/24;
end if;
if region=’Asia-Pac’ then
new_start_date := new_start_date + 15/24;
new_end_date := new_end_date + 15/24;
end if;
–Start After end of day, make start be start of next day
if new_start_date-trunc(new_start_date)>bdayend then
new_start_date := TRUNC(new_start_date+1)+bdaystart;
end if;
–Start before start of day, make start be start of same day
if new_start_date-trunc(new_start_date) < bdaystart then
new_start_date := TRUNC(new_start_date) + bdaystart;
end if;
--Start Saturday, make start be Monday start of day
if to_char(new_start_date,'D')=7 THEN
new_start_date := TRUNC(new_start_date+2)+bdaystart;
END IF;
--Start Sunday, make start be Monday start of day
if to_char(new_start_date,'D')=1 THEN
new_start_date := TRUNC(new_start_date+1)+bdaystart;
END IF;
-- end after end of day, make end be end of day same day
if new_end_date-trunc(new_end_date) > bdayend then
new_end_date := trunc(new_end_date) + bdayend;
end if;
– end before start of day, make end be start of day the same day
if new_end_date-trunc(new_end_date) < bdaystart then
new_end_date := trunc(new_end_date) + bdaystart;
end if;
–end on Saturday, make it be the end of the day on Friday
if to_char(new_end_date,’D')=7 then
new_end_date := trunc(new_end_date-1) + bdayend;
end if;
–end on Sunday, make it be the end of the day on Friday
if to_char(new_end_date,’D')=1 then
new_end_date := trunc(new_end_date-2) + bdayend;
end if;
–factor out weekend days
retval := new_end_date - new_start_date -
((TRUNC(new_end_date,’D') - TRUNC(new_start_date,’D'))/7)*2;
– if holidays were to be calculated, the calculation would go here
– if end is during nonbusiness hours, difference could be negative
if retval < 0 then
retval := 0;
end if;
RETURN(retval);
END;
Oracle analytical function
November 11, 2007 on 11:30 pmI stumbled across a wonderfull website ( http://www.orafusion.com ) that gives us a lot of nice advises on how you might create reports on an Oracle database. How often do we get a request: please give me a pivot table on table xyz in scheme scott, or please give me YTD figures on turn over.
This wonderfull website gives advise on the sql to tackle such questions. Brilliantly written, clear examples. This is the secret toolkit that everybody wants.
Just 2 examples from this website.
I created a table from:
CREATE TABLE “SCOTT”.”KUBUS”
( ”region” VARCHAR2(50 BYTE),
”year” VARCHAR2(20 BYTE),
”value” VARCHAR2(20 BYTE)
);
–REM INSERTING into KUBUS
Insert into KUBUS (region,year,value) values (’gouda’,'1970′,’100′);
Insert into KUBUS (region,year,value) values (’gouda’,'1971′,’110′);
Insert into KUBUS (region,year,value) values (’gouda’,'1972′,’120′);
Insert into KUBUS (region,year,value) values (’haasdrecht’,'1970′,’20′);
Insert into KUBUS (region,year,value) values (’haasdrecht’,'1971′,’22′);
Insert into KUBUS (region,year,value) values (’haasdrecht’,'1972′,’21′);
Then, I created two sql statements. The first is a statement that creates a pivot table:
select
t1.”region”,
t1.”year”,
sum(t1.”value”)
from
KUBUS t1
group by
cube(t1.”region”, t1.”year”)
order by 1, 2
The second one creates a series of YTD figures:
select
t1.”region”,
t1.”year”,
sum(t1.”value”) over (partition by t1.”region”
order by t1.”year” rows unbounded preceding) YTD_sales
from
kubus t1
I derived these statements from the http://www.orafusion.com website. Sure: I will be back on this website to get a better understanding of Oracle analytical functions!
Transferring tables between Oracle instances
November 2, 2007 on 11:41 pmOracle knows several ways to transfer tables between Oracle instances. At least three ways are worth considering.
The first way to transfer tables is to create insert statements, like:
Insert into SCOTT.DEPT DEPTNO, DNAME, LOC)
Values (10, ‘ACCOUNTING’, ‘NEW YORK’);
If such statements are collected in a file, one one subsequently execute the script in another Oracle environment.
The second manner is to use the export utility. This is stored somewhere in client applications (mostly under product\99.99.99\db_1\bin) where a small programme is hidden that allows to export a table. The syntax is something like: exp scott/tiger file=emp.dmp tables=(emp,dept). The file stores a binary formatted table.
The table can subsequently be restored by imp scott/tiger file=emp.dmp fromuser=scott touser=scott tables =dept.
The third way is to use the data pump utility. This is done in two steps. First a general step that creates a so-called directory within Oracle (create directory dpump_dir1 as ‘c:\prive\external’;) with its privileges (grant read, write on directory dpump_dir1 to scott;). This step is taken within sqlplus. Having done this, the pump utility can be used:
expdp scott/tiger directory=dpump_dir1 dumpfile=scott.dmp tables=scott.emp.
Just like the earlier export utility, we get a binary file.
It can be imported by impdp hr/tiger tables=scott.emp directory=dpump_dir1 dumpfile=scott.dmp remap_schema=scott:hr
There are many other ways to exchange tables. Sometimes, I store a table in an Access database, that can easily be transported to another environment.
Anyway: many things to choose from!
Quick overview of Oracle tables
September 19, 2007 on 10:17 amOne may wish to get a quick overview of Oracle tables in a database. One may be interested in an overview of table_names and number of rows. This can be accomplished with the following script:
- DEFINE table_criteria = “table_name = table_name”
- DEFINE dblink = “d552″
- DEFINE owner_criteria = “owner IN (’DWEM’, ‘STO’)”
- SET SERVEROUTPUT ON SIZE 1000000
- SET VERIFY OFF
- DECLARE
- CURSOR c_tables IS
- SELECT table_name
- FROM all_tables@&dblink
- WHERE &table_criteria
- AND &owner_criteria
- ORDER BY table_name;
- v_count1 INTEGER;
- v_rows_fetched INTEGER;
- v_cursor INTEGER := dbms_sql.open_cursor;
- BEGIN
- FOR r1 IN c_tables LOOP
- dbms_sql.parse
- (v_cursor,’SELECT COUNT(*) FROM “‘ || r1.table_name ||’”@&dblink’,dbms_sql.native);
- dbms_sql.define_column (v_cursor, 1, v_count1);
- v_rows_fetched := dbms_sql.execute_and_fetch (v_cursor);
- dbms_sql.column_value (v_cursor, 1, v_count1);
- dbms_output.put_line (r1.table_name || ‘ - ‘ ||LTRIM (TO_CHAR (v_count1, ‘999,999,990′)) ||’ rows on database ‘);
- END LOOP;
- dbms_sql.close_cursor (v_cursor);
- END;
- /
The script is rather straightforward. A cursor is defined that contains all table names that must be investigated.
Then a loop is created that calculates the number of records for each table name involved. In this loop we see some methods. The OPEN_CURSOR function stems from the DBMS_SQL package which opens a cursor and returns a handle. Then the PARSE function checks the syntax of the SQL statement end it associates the SQL statement with the cursor. The EXECUTE_AND_FETCH statement actually executes the SQL statement. As the query returns results, the DEFINE_COLUMN function is executed to contain the results from the query. Finally, the CLOSE function frees the memory.
Protect the data in Oracle
September 12, 2007 on 10:05 pmA recent security feature in Oracle is the TDE (transparent data encryption). Its purpose is to create time slots in which the data are available to everyone. At the other side, during the period that the slot is off, the data can not be seen. It looks a bit like a wallet: when the wallet is open, everyone may take a look. When the wallet is closed, nobody may see the data.
The granularity is at column level: when a column is defined, it can also be stated that the column is encrypted ( SAL NUMBER(7,2) ENCRYPT USING’AES192′SALT iso the ordinary SAL NUMBER(7,2) ).
The time slot during which the data can be seen are switched on by:
alter system set encryption wallet open identified by “[password]”;
Later, the time slot is switched off by:
alter system set wallet close;
Hi that looks convenient! First switch on the wallet, do whatever is needed and then close the wallet. In the off- period, the non-encrypted data can be selected and updated. Only encrypted data are hidden. When an attempt is made to access the data, Oracle returns with an error.
How to create a wallet. This takes 3 steps:
1: Verify that TDE is enabled. This can be assessed with the query “SELECT * FROM V$OPTION ORDER BY VALUE;”. This displays all options available, including TDE.
2: Create a directory on OS level in which the key wallet can be stored. In my case, I created the directory “C:\oracle\product\10.2.0\admin\TomLaptop\wallet”. This is situated alongside the adump directory.
3: Create a password encryption by alter system set encryption key identified by “[password]”;
That is all.
Pumping data in Oracle
August 19, 2007 on 8:16 pmThere are cases when you would like to access data in another database as the one you are in. For example to load data from database A into database B. Or to query two tables: one from database A and another from database B. This can be accomplished in two steps:
1: Create a database link. This can be created via next command: CREATE DATABASE LINK tom10 CONNECT TO scott IDENTIFIED BY bunvegin USING ‘tom10′; In this command “tom10″ “scott” and “bunvegin” must be replaced by your connect string, userID and password. After the invocation of the command, we are able to access data in the database that is meant by the connect string. We can now access the data just as if we would we logged in in the tom10-database as scott/bunvegin. However, we are still in the original database.
2: The tables in the tom10 database can accessed via {table name}@tom10. Example: select count(*) from bonus@tom10.
The queries are run at remarkable speed. I pumped some data from database A to database B. I noticed that the speed was far above the speed that can be gained in the export / subsequent import statements. In short: a nice feauture from Oracle.
Compress the data in Oracle
July 11, 2007 on 10:22 pmThe size of a table can be assessed with next statement:
select bytes/1024/1024 “Size in MB” from user_segments where segment_name=’FEIT’;
where ‘FEIT’ is the name of a table. It may happen that the size of the tables become too large. A response might be to compress the table. Fortunately, this can easily be accomplished with the compression command:
alter table feit move compress;
This command is fairly straight forward. The effect on the size of the table is significant. At the same time, I did not notice any effect on queries. I would have expected that the queries would take longer as data must be uncompressed, but apparently this effect seems to be outweighted by the fact that the number of bytes that are transferred is lower.
I found a nice article( http://www.oracle.com/technology/oramag/oracle/04-mar/o24tech_data.html ) that sums up the pros and cons of compression. In this article, it is mentioned that data loading would take longer. This can be understood as we have the additional time needed to compress the data.
If one would like to decompress the table, one has the command:
alter table feit move nocompress;
This command then returns table “feit” to its original status of non compressed data.
Explain plans in Oracle
July 9, 2007 on 10:03 pmSometimes, you would like to know what is going on in Oracle. In principle such information is revealed if you switch on the autotrace. This is accomplished by “set autotrace on”.
Once a query is run, the underlying actions are revealed. This shows how may read actions are undertaken, how many bytes are sent etc. Comparison of several such outputs displays why a certain query involves more time than another. If one also activates the time (set timing on), one gets an idea why a certain query takes more time than another.
It is also possible to store information on how a qery will be undertaken in the plan table. This is done via: explain plan for select * from dimensie;
The information is then revealed via:
select
substr ( lpad(’ ‘, level-1) || operation || ‘ (’ || options || ‘)’,1,30) “Operation”,
object_name “Object”
from plan_table
start with id = 0
connect by prior id=parent_id;
This command provides us with next results
Operation Object
—————————— ———————–
SELECT STATEMENT ()
TABLE ACCESS (FULL) DIMENSIE
data dumps
June 28, 2007 on 10:27 pmMoving around with large datasets is made possible within Oracle with their datadumps. The idea is that we create a binary file with the table definitions and their data. This file can be moved to another machine on which Oracle runs.
There, on the other machine, the binary file is imported. The table is then recreated and it is loaded with the data.
As an example, we start on the machine that holds two tables that are of interest (emp and dept). First the directory on which the binary is created is declared on Oracle. This is done with the command “create directory”. This command is issued from sqlplus:
in sqlplus:
CREATE OR REPLACE DIRECTORY test_dir AS ‘/u01/app/oracle/oradata/’;
GRANT READ, WRITE ON DIRECTORY test_dir TO scott;
Then the export thru datadump is done with:
on command line:
expdp scott/tiger@tom10 tables=EMP,DEPT directory=TEST_DIR dumpfile=EMP_DEPT.dmp logfile=expdpEMP_DEPT.log
The binary file holds the table definitions and the dta. This file can be moved to another machine. On the other machine the directory is created with:
in sqlplus:
CREATE OR REPLACE DIRECTORY test_dir AS ‘c:\oradata’;
GRANT READ, WRITE ON DIRECTORY test_dir TO scott;
This is followed by an import on the command line:
impdp scott/tiger@ora10 directory=test_dir dumpfile=scott.dmp
That is it.